Training the Model
Now we can actually write the script that will train the model!
# USAGE
# python fine_tune_birds.py --vgg vgg16/vgg16 --checkpoints checkpoints --prefix vggnet
from config import bird_config as config
import mxnet as mx
import argparse
import logging
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-v", "--vgg", required=True,
help="path to pre-trained VGGNet for fine-tuning")
ap.add_argument("-c", "--checkpoints", required=True,
help="path to output checkpoint directory")
ap.add_argument("-p", "--prefix", required=True,
help="name of model prefix")
ap.add_argument("-s", "--start-epoch", type=int, default=0,
help="epoch to restart training at")
args = vars(ap.parse_args())
# set the logging level and output file
logging.basicConfig(level=logging.DEBUG,
filename="training_{}.log".format(args["start_epoch"]),
filemode="w")
# determine the batch
batchSize = config.BATCH_SIZE * config.NUM_DEVICES
# construct the training image iterator
trainIter = mx.io.ImageRecordIter(
path_imgrec=config.TRAIN_MX_REC,
data_shape=(3, 224, 224),
batch_size=batchSize,
rand_crop=True,
rand_mirror=True,
rotate=15,
max_shear_ratio=0.1,
mean_r=config.R_MEAN,
mean_g=config.G_MEAN,
mean_b=config.B_MEAN,
preprocess_threads=config.NUM_DEVICES * 2)
# construct the validation image iterator
valIter = mx.io.ImageRecordIter(
path_imgrec=config.VAL_MX_REC,
data_shape=(3, 224, 224),
batch_size=batchSize,
mean_r=config.R_MEAN,
mean_g=config.G_MEAN,
mean_b=config.B_MEAN)
# initialize the optimizer and the training contexts
opt = mx.optimizer.SGD(learning_rate=5e-5, momentum=0.9, wd=0.0005,
rescale_grad=1.0 / batchSize)
ctx = [mx.gpu(0)]
# construct the checkpoints path, initialize the model argument and
# auxiliary parameters, and whether uninitialized parameters should
# be allowed
checkpointsPath = os.path.sep.join([args["checkpoints"],
args["prefix"]])
argParams = None
auxParams = None
allowMissing = False
# if there is no specific model starting epoch supplied, then we
# need to build the network architecture
if args["start_epoch"] <= 0:
# load the pre-trained VGG16 model
print("[INFO] loading pre-trained model...")
(symbol, argParams, auxParams) = mx.model.load_checkpoint(
args["vgg"], 0)
allowMissing = True
# grab the layers from the pre-trained model, then find the
# dropout layer *prior* to the final FC layer (i.e., the layer
# that contains the number of class labels)
# HINT: you can find layer names like this:
# for layer in layers:
# print(layer.name)
# then, append the string `_output` to the layer name
layers = symbol.get_internals()
net = layers["drop7_output"]
# construct a new FC layer using the desired number of output
# class labels, followed by a softmax output
net = mx.sym.FullyConnected(data=net,
num_hidden=config.NUM_CLASSES, name="fc8")
net = mx.sym.SoftmaxOutput(data=net, name="softmax")
# construct a new set of network arguments, removing any previous
# arguments pertaining to FC8 (this will allow us to train the
# final layer)
argParams = dict({k: argParams[k] for k in argParams
if "fc8" not in k})
# otherwise, a specific checkpoint was supplied
else:
# load the checkpoint from disk
print("[INFO] loading epoch {}...".format(args["start_epoch"]))
(net, argParams, auxParams) = mx.model.load_checkpoint(
checkpointsPath, args["start_epoch"])
# initialize the callbacks and evaluation metrics
batchEndCBs = [mx.callback.Speedometer(batchSize, 50)]
epochEndCBs = [mx.callback.do_checkpoint(checkpointsPath)]
metrics = [mx.metric.Accuracy(), mx.metric.TopKAccuracy(top_k=2),
mx.metric.CrossEntropy()]
# construct the model and train it
print("[INFO] training network...")
model = mx.mod.Module(symbol=net, context=ctx)
model.fit(
trainIter,
eval_data=valIter,
num_epoch=65,
begin_epoch=args["start_epoch"],
initializer=mx.initializer.Xavier(),
arg_params=argParams,
aux_params=auxParams,
optimizer=opt,
allow_missing=allowMissing,
eval_metric=metrics,
batch_end_callback=batchEndCBs,
epoch_end_callback=epochEndCBs)A few important things to note:
- This script makes use of a pretrained imagenet model so you'll need to provide those pretrained weights: params & symbols
- I've included top k 2 accuracy which is a literally useless metric but the 2 can just be incremented to a more useful metric when I have more categories of training data ready
- The hyperparameters used here are probably terrible but it doesn't make sense to worry about those when we still have so little training data
- I'm training with a single GTX 1080 graphics card so my ctx variable is set to [mx.gpu(0)]. Add more cards to that list and change the NUM_DEVICES variable in the config file if you have more cards to train with
Checking the Output
The good news is that it runs! An exert of my training_0.log file looks like this:
INFO:root:Epoch[0] Train-accuracy=0.710938
INFO:root:Epoch[0] Train-top_k_accuracy_2=1.000000
INFO:root:Epoch[0] Train-cross-entropy=0.704148
INFO:root:Epoch[0] Time cost=4.002
INFO:root:Saved checkpoint to "/ML/Birds/checkpoints/vggnet-0001.params"
INFO:root:Epoch[0] Validation-accuracy=0.812500
INFO:root:Epoch[0] Validation-top_k_accuracy_2=1.000000
INFO:root:Epoch[0] Validation-cross-entropy=0.392680
INFO:root:Epoch[1] Train-accuracy=0.812500
INFO:root:Epoch[1] Train-top_k_accuracy_2=1.000000
INFO:root:Epoch[1] Train-cross-entropy=0.394014
INFO:root:Epoch[1] Time cost=3.758
INFO:root:Saved checkpoint to "/ML/Birds/checkpoints/vggnet-0002.params"
INFO:root:Epoch[1] Validation-accuracy=0.906250
INFO:root:Epoch[1] Validation-top_k_accuracy_2=1.000000Classes: 2
Training Images: 372
Validation Images: 72
We can also graph the data from the training logs to get a better idea of how it's doing.

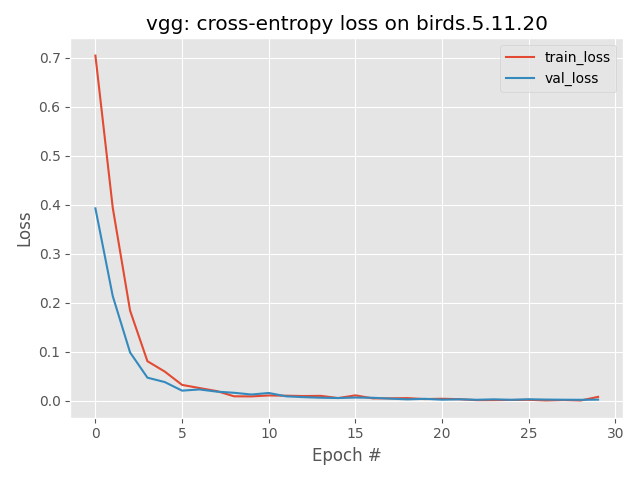
The graphs look pretty good but that's just because the model is able to overfit super quickly since there are so few data to learn from. I also haven't yet fixed the problem of images without birds being incorrectly classified so there's no reason too read to much into these results. Since we know the data being fed to the model isn't high quality yet, we know that the output can't be of high quality. So really this is a good example of why you should be skeptical of the output of machine learning models until you've thoroughly scrutinized them.
Now that I know that the training pipeline is actually functional, I can focus my efforts on building a more robust training set. Then we can fuddle with the hyperparameters and actually start thinking more critically about the results that we're getting.